Supervised Learning: An Introduction
Least-squares
The assumption is that \(f(X) = E(Y|X)\) is linear.
Here, \(X \in R^{n \times (p+1)}\) where the extra parameter is a column of ones for the intercept \(\beta_0\).
We assume that \(Y = E(Y|X) + \epsilon\) where \(\epsilon\) captures the tangents not captured by the predictors (e.g. noise) and \(\epsilon \sim N(0, \sigma_{\epsilon}^2)\) independent from \(X\).
Where the \(\beta_0\) term is the model bias. The gradient \(f^\prime(X) = \beta\) is a vector in input space that points in the steepest uphill direction. To fit the model, a (simple) method is least squares. Here, we pick coefficients \(\beta\) to minimize the residual sum of squares
which shows a quadratic function of the parameters. Therefore, a minimum always exists but may not be unique. In matrix notation,
where X is an \(N \times p\) matrix with each row a sample, and y is an N-vector of the outputs in the training set. Differentiating w.r.t. \(\beta\) we get the normal equations
If \(X^T X\) is nonsingular (i.e. invertible, \(AB = BA = I\)), then the unique solution is given by
The projection matrix (or hat matrix) \(H=X(X^T X)^{-1} X^T\). Our observation \(y\). We estimate \(\hat{y}\). The best we can do is find the projection of \(y\) on the \(X\) space.It should happen that the residual (vertical projection axis) should be indpeendent of \(\hat{y}\) because the best linear prediction will have no systematic bias. The length of the residual is longer than the current \(y\).
Error is \(y - \hat{y} = (I - H)Y\). We must check whether
Because we know \(E[Y|X] = XB + \epsilon\),
Because \(\epsilon \epsilon^T = \sigma_{\epsilon}^2 I\), we conclude that
We know $HH = X(X^T X)^{-1} X^T X(X^T X)^{-1} X^T = X(X^T X)^{-1} X^T $
Projecting \(y\) to the space that is orthogonal to the \(X\) plane is defined by \(I-H\). When we multiply this times \(H\), we get \(H-HH = 0\).
If given a new input, then the same thing applies.
We know \(RSS\) increases with degrees of freedom, so we use residual stnanard error (RSE) instead:
This is an unbiased estimator: \(\sigma_{\epsilon}^2 = \frac{RSS}{N - (p+1)} = RSE^2\)
Therefore, a solution for the best \(\beta\) can be found without iteration.
A “poor man’s” classifier can use linear regression and predict \(1(\hat{Y} > 0.5)\). Ideally, we would like to estimate \(P(Y=1|X=x)\)
Additionally,
Because \(tr(AB) = tr(BA)\), we know \(tr(H) = tr(X(X^T X)^{-1} X^T) = tr((X^T X)^{-1} X^T X) = tr(I p + 1) = p + 1\). To understand residuals, we can understand how bad an outlier is.
\(Var(\hat{\epsilon}) = Var(y - \hat{y}) = (1 - H) \hat{\sigma}_\epsilon^2\)
\(Var(\hat{\epsilon}_i) = (1 - h_i) \hat{\sigma}_\epsilon^2\). This grants \(H\) an important role to calculate variance of residuals. If we have a large \(h_i\) then the residual has to have a small variance. This is called leverage.
For simple linear regression (p=1), \(h_i = \frac{1}{n} + \frac{(x_i - \bar{x})^2}{\sum_j (x_j - \bar{x})^2}\). Where the ratio \(\frac{(x_i - \bar{x})^2}{\sum_j (x_j - \bar{x})^2}\) is the variance, which is always between 0 and 1.
We can standardize the epsilon by the variance (resulting in a t-distribution).
A large \(r_i\), . For instance if \(r_i = -2.5\), then the point is at 2.5 percent tail. A large \(r_i\) is an outlier.
Cook’s distance shows the model evaluation when if the model did not use a specific sample.
As shown here, an influential point must have high leverage and a high standard residual. We call this influence, as in it has a large influence on the final model.
On a plot of sqrt of standardized residuals vs fitted values, if you see a nonlinear pattern, then you may want to transform. The constant residual assumption. Consider transforming X instead of Y. (If you have heteroscedasticity, consider transforming Y). https://stats.stackexchange.com/questions/116486/why-y-should-be-transformed-before-the-predictors
On a plot of standradized rewiduals vs leverage, If near contour, the corresponding cooke’s distance will be 0.5. If you observe a point outside 1, then it’s a very influential point. If 0.5 to 1, it’s influential but not as extreme.
How do we evaluate our linear model?
We use the residual sum of errors (RSE): the smaller the better. This depends on the unit and scale of the response.
\(R^2\) instead measures the proportion of variance explained by regression.
We can only assume that all of the Ys are IID, so in this case, we get a horizontal line (at the mean). the total variability not explained by the model
\(SSE\) (or \(RSS\)), as described above, measures from the data point to the regression line. the total variability explained by the model. (\(=SST - SSR\))
\(SSR\) measures from the regression line to the mean (horizontal line).
\(SST\) measures from the data point to the mean, defines the total variability in your dataset
We know that \(SST = SSE + SSR\).
\(R^2\) (r-squared, r squared) measures the proportion of variability which can be explained by the model.
For simple linear regression, \(Y = \beta_0 + \beta_1 X + \epsilon\), \(R^2 = r^2\), where \(r\) is the pearson correlation. The pearson correlation coefficient is
It measures how strong X and Y are correlated, and is in range [-1,1].
Question: Can we get \(F\)-statistic from \(R^2\)?
Yes. We know \(n\) (number of samples), \(p\) is number of parameters. We know $y =
Statistical Inference
A random sample \(X_1, X_2, ..., X_n\) be i.i.d., a statistic \(T = T(X_1, X_2, ..., X_n)\) is a function of the random sample. Let’s say this is the mean. The estimator \(\hat{\theta} = \hat{\theta}(X_1, X_2, ..., X_n)\). Our hypothesis could be to conclude if \(H_0 : \theta = \theta_0\) (two-sided).
There are two types of errors (type 1 and type 2).
p-value: Probability obtaininga value of statistic more extreme than the observed value \(H_0\). This mimics type 1 error.
Confidence interval: \(CI(X_1, X_2, ..., X_n)\) interval constructed from the random sample such that \(PR(\theta \in CI(X_1, X_2, ..., X_n)) = 1 - \alpha\). The narrower the confidence is, the more specific the estimation, given a pre-specified confidence level.
Common distributions
If \(Z_i \sim N(0,1)\), i.i.d. then \(\sum_i Z_i^2 \sim \chi_n^2\) where \(n\) is the number of RVs.
If \(Z \sim N(0,1)\) and \(W \sim \chi_n^2\) and they are independent then \(frac{Z}{\sqrt{W/n}} \sim t_n\). For instance, the ratio of the \(\bar{x}\) and sample standard deviaiton \(s^2\)
If \(W_1 \sim \chi_n^2\) and \(W_2 \sim X_m^2\) adn they are independent then \(F_{n,m}\). For instance if SSE / SSR is large enough.
Significance t-tests of coefficients
Check importance of the coefficients. Generally, if \(\beta_j = 0\), then we say that the predictors are not aiding the model’s prediction abilities.
\(H_0 : \beta_j = 0\) and \(H_1: \beta_j \neq 0\)
Note \(\hat{\beta} = (X^T X)^{-1} X^T (X \beta + \epsilon)\)
Given \(X\), \(\hat{\beta} \sim N(\beta, (X^T X)^{-1} \sigma_\epsilon^2)\). The expected value is therefore: \(\beta\).
Also, \(Cov(\hat{\beta}, \hat{\beta}) = E[(\hat{\beta} - \beta) (\hat{\beta} - \beta)^T]E(Y|X) = X\beta\)
The Z-score for each \(\hat{\beta_j}\) is
Under null (\(\hat{\beta} = 0\)), we should get \(z_j \sim t_{N-p-1}\).
More goodness of fit
Bringing in more predictors will reduce SSE naturally (and increase \(R^2\)). Instead, we can do a hypothesis test.
SSR is independnet of SSE. We define the F-statistic
then \(F \sim F_{p, N-p-1}\). The p-value is \(Pr(F_{p,N-p-1} \geq F)\). If large F then reject.
There are two parameters to define a line (an intercept and a slope), so if have more predictors (p) then you will have \(p\) degrees of freedom for SSR. Residual has \(p\) predictors and \(1\) y-intercept.
Question: Is t-test and f-test equivalent for simple linear regression?
Answer: Yes!
Nearest neighbors
For regression, calculates average values of the \(k\) nearest neighbors. This replaces the expected value (in normal regression) with the sample average. For classification, a majority vote is conducted.
If large number of variables, it’ll require a larger number \(k\). If kept same, then smaller number of neighbors will be included (Curse of dimensionality). Increased number of features, the definition of the neighborhood will also have to expand. The bias increases. This is because as you add another feature, it’ll inherently make the points be further apart.
Also, as you increase \(k\), a smoother surface will be formed (i.e. reduced variance).
The best \(k\) can be found empirically.
Bias-variance tradeoff
For a fixed \(x_0\),
We know that \(E[\hat{f}(x_0) - E\hat{f}(x_0)] = 0\). Therefore,
There is no bias if \(k=1\) in nearest neighbor analysis. Small \(k\) is small bias but high variance. Large \(k\) is the summation over \(n\) so benefiting from Variance (because for sample variance, there is a \(\frac{1}{n}\) term) will be low but bias will be high.
Linear regression vs. kNN
Linear regression has high bias (linear assumption can be violated) but only needs to estimate p+1 parameters.
kNN uses \(\frac{n}{k}\) parameters but is flexible and adaptive. It is small bias but large variance.
Interval prediction
Confidence interval
A confidence interval of \(f(X) = \sum_{j=0}^p \beta_j x_j\) for given \(x=(x_0,...,x_p)^T\) is
Why? Hint: What is the distribution of \(\vec{x}^T \hat{\beta}\), where \(\vec{x} = (x_0=1, x_1, ..., x_p)^T\)?
Prediction interval
A confidence interval of \(y = \sum_{j=0}^p \beta_j x_j + \epsilon\) for given \(x=(x_0,...,x_p)^T\) is
\(\sum(\beta_j x_j - \hat{\beta}_j x_j)\). The CI of \(\beta_j x_j\) is calculated above.
This is the same as $y - \hat{y} = y - \sum `:nbsphinx-math:hat{beta}`_j x_j = \epsilon `+ :nbsphinx-math:sum :nbsphinx-math:beta`_j x_j \sum `:nbsphinx-math:hat{beta}`_j x_j $
Review of Conditional Expectation
The conditional expected value is just the expectation when X is specified.
Conditional expectation is a random variable. Without specificing \(X=x\), \(E(Y|X)\) is a function of \(X\). Because \(X\) is a RV, then \(E(Y|X)\) is also RV.
Tower property: \(E(Y) = E[E(Y|X)]\).
We say that \(X\) takes a fixed value such as \(x_0 = 0\), then \(g(x_0)\) is deterministic (i.e. not random). Its form may be unknown, or involves unknown parameters, e.g.
Example
\(Y = a X^2 + \epsilon\), \(\epsilon\) ind \(X\), \(\epsilon \sim N(0,1)\)
\(E(Y|X) = E(c + X^2 + \epsilon | X) = c + X^2 + E(\epsilon|X) = c + X^2\) where \(E(\epsilon|X)=0\)
Example
\(Y = X^2 + 10X + 20 + \epsilon\)
where \(\epsilon \sim N(0, 3)\) and \(X \sim N(30,10)\)
In this case, we know the underlying probability model.
The joint distribution gives a lot of information!
We can evalaute for the best model \(f\) by minimizing a loss function (i.e. \(L(Y, f(X)) = Y - f(X))^2\))
Because we have assumed that we know the joint distribution (and it’s all continuous), then we evaluate an integral.
The best f is E(Y|X=x)
^ This depends on your loss function! (using squared loss!) If you use L1 then your best \(f\) will be at the median. Squared loss is better because can take derivative of it. However, it can be influenced by extreme values.
Minimize \(E[(Y - f(x)]^2 | X)\) for every X. This can be decomposed
With \(A = Y - E(Y|X)\) and \(B = E(Y|X) - f(X)\)
We know that at a given \(X\), \(A \times B\) is a constant.
Therefore, \(EPE(f) = EPE(E(Y|X)) + B\)
If the population is known, then \(f(x) = \int y f_{Y|X} (y|x) dy\) simply. This is the ideal case where you have population. However, this is rare.
For Example, if \(Y\) is a known funtion of \(X\) (with some error), then you know the conditional distribution. From this, you can estimate \(f\) as the mean of that conditional distribution.
Categorical classification
Loss matrix can be used to penalize categories heavier.
For example, in stock market prediction, we may place a heavier scaler on the loss function for when the stock market
Popular choice: \(L = 1_{K \times K} - I_K\) forms a matrix of ones except for zeros in the diagonal (because no update should be made if it is correct). This can also be expressed as \(L(G, \hat{G}(X)) = I(G \neq \hat{G}(X))\).
The solution that minimizes the EPE is \(\hat{G}(x) = arg max_g Pr_{G|X} (g|x)\). The group that maximizes the conditional probability \(Pr_{G|X}(g|x)\). This is called the bayes classifier. Its error is called the bayes rate. The group has a prior (original) distribution. For example, increasing and decreasing is equally likely. According to yesterday’s information, update and calculate posterior probability \(Pr_{G|X}(g|x)\).
Example
Generate \(X|G \sim N(\mu_G, I_2)\) where two centers are defined: \(\mu_1 = (0,1)^T, \mu_2 = (1,0)^T\)
Because this was generated, we know the labels: \(G_{1}, ..., G_{100} = 1\) and \(G_{101}, ..., G_{200} = 2\).
The bayes classifier is found by assuming the joint distribution \(X|G \sim N(\mu_G, I_2)\). Therefore, each group is equally likely. The boundary between these two groups is found by
$E(1(G|X)) = P(G=1|x_0) $ versus \(P(G=2|x_0)\) and the larger one is chosen for the point.
At the beginning, \(P(G=1) = P(G=2) = 0.5\).
At a sample located at \(\vec{X} = (10,9)\), the expectation can be evaluated by \(P(G_j = 1 | x_0 = (10,9)) = f(x_0 = (10,9)) = \frac{f(x_0 = (10,9) | G=1)}{f_x( (10, 9) )}\)
\(f_{N(0,1)}(x_0, x_1)\) is the double normal distribution (a function of X2 and X1).
So plug in the likelihood of observing the X multiplied by the given distribution (per bayesian rule). Bayes rule finds the ratio of the joint probability
Linear regression
With a feature \(p=1\), what is the estimated \(\beta\)?
Solution: Take the derivative and then set equal to zero. RSS will have a minimum.
\(RSS(\beta_0, \beta_1) = y - X\beta\)
Exercises
Exercise: Suppose each of \(K\)-classes has an associated target \(𝑡_𝑘\), which is a vector of all zeros, except a one in the \(k\)th position. Show that classifying to the largest element of \(\hat{y}\) amounts to choosing the closest target, \(min_{k} ||t_k - \hat{y}||\), if the elements of \(\hat{y}\) sum to one.
Proof:
where \(t_k \in T\).
The model predicts \(Pr(y_i = t_k)\) where
For the first term, when \(k=i\), the quantity equals 1 else it is 0. Thus, $:nbsphinx-math:sumi t{k,i}^2 = 1 for all values of \(k\). Likewise, the last term of \(\sum_i y_i^2\) is independent of \(k\) so that it is constant wrt \(k\). Finally, the middle term $:nbsphinx-math:sumi -2 t{k,i} y_i = -2 y_i when \(k=i\) and is 0 otherwise. Note that it also varies across different values of \(k\) so that it is a function of \(k\). Then, we can rewrite the above function as a function of only the middle term as follows:
Multiplying the above quantity by (-1), we can change the min to a max problem.
Therfore, we state that the largest element in \(\hat{y}\) is the closest target.
Excercise: Show how to compute the bayes decision boundary for the simulation example in Figure 2.5
[6]:
from utils import disp
disp('bayes_decision_boundary.png')
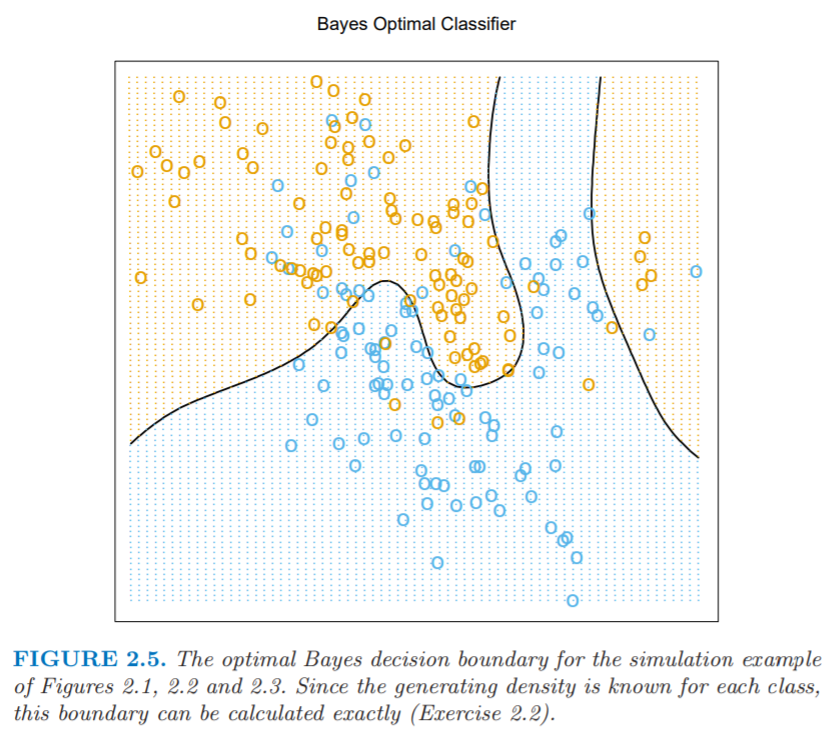
Proof:
Above, we see two classes, generated by a mixture of Gaussians. Our generating density is \(N(m_k, I / 5)\) is a weighted sum of 10 Gaussians generated from \(N((0,1)^T, I)\).
Bayes classifier says that we classify to the most probable class using the conditional distribution \(Pr(G|X)\). Hence, the decision boundary is the set of points that partitions the vector space into two sets: one for each class. On the decision boundary itself, the output label is ambiguous.
Boundary = \(\{ x: max_{g \in G} Pr(g | X=x) = max_{k\in G} Pr(k | X=x)\}\)
It is the set of points where the most probable class is tied between two or more classes.
In the case of two examples,
Boundary = \(\{ x: Pr(g|X=x) = Pr(k|X=x)\} = \{ x: \frac{Pr(g|X=x)}{Pr(k|X=x)} = 1 \}\)
We can rewrite the above quantity by Bayes rule as follows:
\(\frac{Pr(g|X=x)}{Pr(k|X=x)} = \frac{Pr(X=x|g) Pr(g) / Pr(X=x)}{Pr(X=x|k) Pr(k) / Pr(X=x)} = \frac{Pr(X=x | g) Pr(g)}{Pr(X=x|k) Pr(k)} = 1\)
because we have 100 points in each class, so \(Pr(g) = Pr(k)\). The boundary becomes \(\{x: Pr(X=x|g) = Pr(X=x|k) \}\). We know \(Pr(X=x|g)\) because we know the generating density is gaussian. So,
We take the log to ensure a monotonic function
Equating class \(g\) and \(k\) to get the decision boundary, we get
Boundary = \(\{ x: \sum_{k=1}^{10} \ln( \frac{1}{5 \sqrt{2 \pi}}) - \frac{(x - m_k)^2}{2 \times 25} = \sum_{k=1}^{10} \ln( \frac{1}{5 \sqrt{2 \pi}}) - \frac{(x - n_i)^2}{2 \times 25} \}\)
The observations of cluster 1 (\(m_k\)) and cluster 2 (\(n_i\)) help generate the exact boundary.
[7]:
import numpy as np
import pandas as pd
class KNearestNeighbors():
def __init__(self, X_train, y_train, n_neighbors=5, weights='uniform'):
self.X_train = X_train
self.y_train = y_train
self.n_neighbors = n_neighbors
self.weights = weights
self.n_classes = len(np.unique(y_train))
def euclidian_distance(self, a, b):
return np.sqrt(np.sum((a - b)**2, axis=1))
def kneighbors(self, X_test, return_distance=False):
dist = []
neigh_ind = []
point_dist = [self.euclidian_distance(x_test, self.X_train) for x_test in X_test]
for row in point_dist:
enum_neigh = enumerate(row)
sorted_neigh = sorted(enum_neigh,
key=lambda x: x[1])[:self.n_neighbors]
ind_list = [tup[0] for tup in sorted_neigh]
dist_list = [tup[1] for tup in sorted_neigh]
dist.append(dist_list)
neigh_ind.append(ind_list)
if return_distance:
return np.array(dist), np.array(neigh_ind)
return np.array(neigh_ind)
def predict(self, X_test):
if self.weights == 'uniform':
neighbors = self.kneighbors(X_test)
print(neighbors)
y_pred = np.array([
np.argmax(np.bincount(self.y_train[neighbor]))
for neighbor in neighbors
])
return y_pred
if self.weights == 'distance':
dist, neigh_ind = self.kneighbors(X_test, return_distance=True)
inv_dist = 1 / dist
mean_inv_dist = inv_dist / np.sum(inv_dist, axis=1)[:, np.newaxis]
proba = []
for i, row in enumerate(mean_inv_dist):
row_pred = self.y_train[neigh_ind[i]]
for k in range(self.n_classes):
indices = np.where(row_pred == k)
prob_ind = np.sum(row[indices])
proba.append(np.array(prob_ind))
predict_proba = np.array(proba).reshape(X_test.shape[0],
self.n_classes)
y_pred = np.array([np.argmax(item) for item in predict_proba])
return y_pred
def score(self, X_test, y_test):
y_pred = self.predict(X_test)
return float(sum(y_pred == y_test)) / float(len(y_test))
data = np.array(
[
[0,3,0,1],
[2,0,0,1],
[0,1,3,1],
[0,1,2,0],
[1,0,1,0],
[1,1,1,1]
]
)
X = data[:,0:3]
y = data[:,-1]
k = 3
knn = KNearestNeighbors(X,y,n_neighbors=k)
knn.predict([[0,0,0]])
[[4 5 1]]
[7]:
array([1], dtype=int64)
[10]:
import matplotlib.pyplot as plt
import numpy as np
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score
np.random.seed(1234)
alpha = 0.95
cov = [[1, 0], [0, 1]] # diagonal covariance
mean0 = np.array([0, 1])
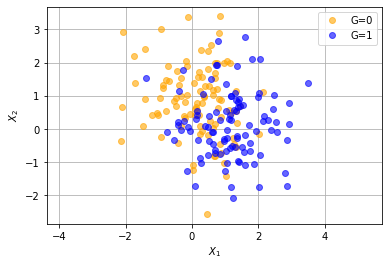
x, y = np.random.multivariate_normal(mean0, cov, 100).T
plt.plot(x, y, 'o', color='orange', label='G=0', alpha=0.6)
mean1 = np.array([1, 0])
x2, y2 = np.random.multivariate_normal(mean1, cov, 100).T
plt.plot(x2, y2, 'bo', label='G=1', alpha=0.6)
plt.axis('equal')
plt.legend()
plt.xlabel(r'$X_1$')
plt.ylabel(r'$X_2$')
plt.grid('..')
plt.show()
X = np.append(np.column_stack((x,y)), np.column_stack((x2,y2)), axis=0)
Y = np.append(np.zeros(len(x)), np.ones(len(x2))).astype(float)
nneighbors = [1,10,20,100]
accs = []
for n in nneighbors:
neigh = KNeighborsClassifier(n_neighbors=n)
neigh.fit(X, Y)
yhat = neigh.predict(X)
acc = accuracy_score(Y, yhat)
accs.append(1 - acc)
plt.plot(nneighbors, accs, 'o-')
plt.xlabel(r'$k$ neighbors')
plt.ylabel('Error rate')
plt.show()
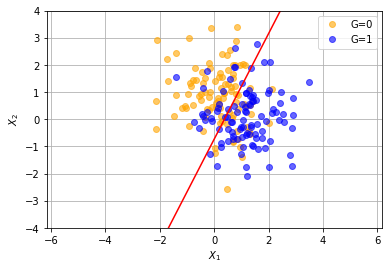
plt.plot(x, y, 'o', color='orange', label='G=0', alpha=0.6)
plt.plot(x2, y2, 'bo', label='G=1', alpha=0.6)
plt.axis('equal')
plt.legend()
plt.xlabel(r'$X_1$')
plt.ylabel(r'$X_2$')
plt.grid('..')
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
lda = LinearDiscriminantAnalysis()
lda_object = lda.fit(X, Y)
print('m', lda_object.coef_)
print('b', lda_object.intercept_)
x1 = np.array([np.min(X[:,0], axis=0), np.max(X[:,0], axis=0)])
i = 0
c = 'r'
b, w1, w2 = lda.intercept_[i], lda.coef_[i][0], lda.coef_[i][1]
print(b, w1, w2)
y1 = -(b+x1*w1)/w2
plt.plot(x1,y1,c=c)
plt.xlim(-3,3)
plt.ylim(-4,4)
plt.show()

m [[ 1.15981357 -0.59760123]]
b [-0.43829084]
-0.4382908386736625 1.1598135678848691 -0.5976012319170687
[16]:
import collections
import numpy as np
from numpy import sqrt, exp
def pre_prob(y):
y_dict = collections.Counter(y)
pre_probab = np.ones(2)
for i in range(0, 2):
pre_probab[i] = y_dict[i]/y.shape[0]
return pre_probab
def mean_var(X, y):
n_features = X.shape[1]
m = np.ones((2, n_features))
v = np.ones((2, n_features))
n_0 = np.bincount(y)[np.nonzero(np.bincount(y))[0]][0]
x0 = np.ones((n_0, n_features))
x1 = np.ones((X.shape[0] - n_0, n_features))
k = 0
for i in range(0, X.shape[0]):
if y[i] == 0:
x0[k] = X[i]
k = k + 1
k = 0
for i in range(0, X.shape[0]):
if y[i] == 1:
x1[k] = X[i]
k = k + 1
for j in range(0, n_features):
m[0][j] = np.mean(x0.T[j])
v[0][j] = np.var(x0.T[j])*(n_0/(n_0 - 1))
m[1][j] = np.mean(x1.T[j])
v[1][j] = np.var(x1.T[j])*((X.shape[0]-n_0)/((X.shape[0]
- n_0) - 1))
return m, v # mean and variance
def prob_feature_class(m, v, x):
n_features = m.shape[1]
pfc = np.ones(2)
for i in range(0, 2):
product = 1
for j in range(0, n_features):
product = product * (1/sqrt(2*np.pi*v[i][j])) * exp(-0.5
* pow((x[j] - m[i][j]),2)/v[i][j])
pfc[i] = product
return pfc
def GNB(X, y, x):
m, v = mean_var(X, y)
pfc = prob_feature_class(m, v, x)
pre_probab = pre_prob(y)
pcf = np.ones(2)
total_prob = 0
for i in range(0, 2):
total_prob = total_prob + (pfc[i] * pre_probab[i])
for i in range(0, 2):
pcf[i] = (pfc[i] * pre_probab[i])/total_prob
prediction = int(pcf.argmax())
return m, v, pre_probab, pfc, pcf, prediction
Y = Y.astype(int)
# executing the Gaussian Naive Bayes for the test instance...
m, v, pre_probab, pfc, pcf, prediction = GNB(X, Y, np.array([2,2]))
print(m) # Output given below...(mean for 2 classes of all features)
print(v) # Output given below..(variance for 2 classes of features)
print(pre_probab) # Output given below.........(prior probabilities)
print(pfc) # Output given below............(posterior probabilities)
print(pcf) # Conditional Probability of the classes given test-data
print(prediction) # Output given below............(final prediction)
[[0.12908891 0.85586925]
[1.13164542 0.12410715]]
[[0.79127964 1.14334245]
[0.84673467 0.96361033]]
[0.5 0.5]
[0.01034183 0.01819066]
[0.36245814 0.63754186]
1
[53]:
import pandas as pd # for data manipulation
import numpy as np # for data manipulation
from sklearn.model_selection import train_test_split # for splitting the data into train and test samples
from sklearn.metrics import classification_report # for model evaluation metrics
from sklearn.preprocessing import OrdinalEncoder # for encoding categorical features from strings to number arrays
import plotly.express as px # for data visualization
import plotly.graph_objects as go # for data visualization
# Differnt types of Naive Bayes Classifiers
from sklearn.naive_bayes import GaussianNB
from sklearn.naive_bayes import CategoricalNB
from sklearn.naive_bayes import BernoulliNB
# Function that handles sample splitting, model fitting and report printing
def mfunc(X, y, typ):
# Create training and testing samples
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
# Fit the model
model = typ
clf = model.fit(X_train, y_train)
# Predict class labels on a test data
pred_labels = model.predict(X_test)
# Print model attributes
print('Classes: ', clf.classes_) # class labels known to the classifier
if str(typ)=='GaussianNB()':
print('Class Priors: ',clf.class_prior_) # prior probability of each class.
else:
print('Class Log Priors: ',clf.class_log_prior_) # log prior probability of each class.
# Use score method to get accuracy of the model
print('--------------------------------------------------------')
score = model.score(X_test, y_test)
print('Accuracy Score: ', score)
print('--------------------------------------------------------')
# Look at classification report to evaluate the model
print(classification_report(y_test, pred_labels))
# Return relevant data for chart plotting
return X_train, X_test, y_train, y_test, clf, pred_labels
y = Y
# Fit the model and print the result
X_train, X_test, y_train, y_test, clf, pred_labels, = mfunc(X, y, GaussianNB())
# Specify a size of the mesh to be used
mesh_size = 5
margin = 5
# Create a mesh grid on which we will run our model
x_min, x_max = np.min(X[:,0]) - margin, np.max(X[:,0]) + margin
y_min, y_max = np.min(X[:,1]) - margin, np.max(X[:,1]) + margin
xrange = np.arange(x_min, x_max, mesh_size)
yrange = np.arange(y_min, y_max, mesh_size)
xx, yy = np.meshgrid(xrange, yrange)
# Create classifier, run predictions on grid
Z = clf.predict_proba(np.c_[xx.ravel(), yy.ravel()])[:, 1]
Z = Z.reshape(xx.shape)
# Specify traces
trace_specs = [
[X_train, y_train, 0, 'Train', 'brown'],
[X_train, y_train, 1, 'Train', 'aqua'],
[X_test, y_test, 0, 'Test', 'red'],
[X_test, y_test, 1, 'Test', 'blue']
]
# Build the graph using trace_specs from above
fig = go.Figure(data=[
go.Scatter(
x=X[y==label,0], y=X[y==label,1],
name=f'{split} data, Actual Class: {label}',
mode='markers', marker_color=marker
)
for X, y, label, split, marker in trace_specs
])
# Update marker size
fig.update_traces(marker_size=5, marker_line_width=0)
# Update axis range
#fig.update_xaxes(range=[-1600, 1500])
#fig.update_yaxes(range=[0,345])
# Update chart title and legend placement
fig.update_layout(title_text="Decision Boundary for Naive Bayes Model",
legend=dict(orientation="h", yanchor="bottom", y=1.02, xanchor="right", x=1))
# Add contour graph
fig.add_trace(
go.Contour(
x=xrange,
y=yrange,
z=Z,
showscale=True,
colorscale='magma',
opacity=1,
name='Score',
hoverinfo='skip'
)
)
fig.show()
Classes: [0 1]
Class Priors: [0.5125 0.4875]
--------------------------------------------------------
Accuracy Score: 0.775
--------------------------------------------------------
precision recall f1-score support
0 0.76 0.72 0.74 18
1 0.78 0.82 0.80 22
accuracy 0.78 40
macro avg 0.77 0.77 0.77 40
weighted avg 0.77 0.78 0.77 40
Data type cannot be displayed: application/vnd.plotly.v1+json
[6]:
import numpy as np
from scipy import stats
from pprint import pprint
np.random.seed(1)
n = 100
p = 1
model_type = 'y=f(x)'
#model_type = 'x=f(y)'
#add_intercept = False
add_intercept = True
df = pd.read_csv('_static//datamining_hw2_question2.csv')
xx = df['x'].values
yy = df['y'].values
# GENERATE DATA IN PYTHON
# xx = np.random.normal(0,1,n)
# yy = 2 * xx + np.random.normal(0,1,n)
if model_type == 'y=f(x)':
y = yy
x = xx
elif model_type == 'x=f(y)':
y = xx
x = yy
if add_intercept:
xvec = np.hstack((np.vstack(np.ones(len(x))),np.vstack(x)))
else:
xvec = np.vstack(x)
def f(arr):
if add_intercept:
return m[0] + m[1] * arr
else:
return m * arr
m = np.dot(np.linalg.inv(np.dot(xvec.T, xvec)), np.dot(xvec.T, y))
# also, m, _, _, _ = np.linalg.lstsq(xvec, y)
yhat = f(x)
print('constants', m)
def analyze_linear_model(y, yhat, x, n, p):
ybar = np.sum(y)/len(y)
residuals = y - yhat
SSR = np.sum((yhat - ybar)**2)
SST = np.sum((y - ybar)**2)
SSE = np.sum((y - yhat)**2) # or residuals.T @ residuals
RSE = np.sqrt(SSR / (n - 2))
MSE = (sum((y-yhat)**2))/(n-p)
correlation_r = []
for col in range(x.shape[1]):
correlation_r.append(np.cov(x[:,col],y)[0][1]/ (np.std(x[:,col]) * np.std(y)))
sigma_squared_hat = SSE / (n - p)
var_beta_hat = (np.linalg.inv(xvec.T @ xvec) * sigma_squared_hat)[0][0]
# or var_beta_hat = MSE*(np.linalg.inv(np.dot(xvec.T,xvec)).diagonal())
sd_b = np.sqrt(var_beta_hat)
ts_b = m/ sd_b
p_ttest =2*(1-stats.t.cdf(np.abs(ts_b),(n - p)))
F = (SSR/p)/(SSE/(n - p - 1))
p_ftest = stats.f.cdf(F, p, n-p-1)
R2_another_calc = 1 - (1 + F * (p) / (n - p - 1))**(-1)
# print("r2 another way", R2_another_calc)
info = {'SSR': SSR,
'SSE': SSE,
'SST': SST,
'r2': SSR / SST,
'RSE': RSE,
'MSE': MSE,
'r': correlation_r,
'Var(Bhat)': var_beta_hat,
'Sd(Bhat)': sd_b,
't(Bhat)': ts_b,
'p_ttest(Bhat)': p_ttest,
'F(Bhat)': F,
'p_ftest(Bhat)': p_ftest
}
pprint(info)
import statsmodels.api as sm
model = sm.OLS(y,x)
results = model.fit()
results_summary = results.summary()
print(results_summary)
analyze_linear_model(y, yhat, xvec, n, p)
# Approximate form of t-test (for a no-intercept model)
approx_t_bhat = (np.sqrt(n - 1) * np.sum(x * y)) / np.sqrt(np.sum(x**2) * np.sum(y**2) - (np.sum(x * y))**2)
'approx_t_bhat', approx_t_bhat
constants [-0.03769261 1.99893961]
{'F(Bhat)': 344.31026392149494,
'MSE': 0.9175314048171069,
'RSE': 1.8045834713513378,
'SSE': 90.83560907689355,
'SSR': 319.1391074972955,
'SST': 409.97471657418896,
'Sd(Bhat)': 0.09649621618971455,
'Var(Bhat)': 0.009311519738932126,
'p_ftest(Bhat)': 0.9999999999999999,
'p_ttest(Bhat)': array([0.69692306, 0. ]),
'r': [nan, 0.8912022644583839],
'r2': 0.7784360707998542,
't(Bhat)': array([-0.39061235, 20.7152124 ])}
<ipython-input-6-9a69040a4fca>:61: RuntimeWarning: invalid value encountered in double_scalars
correlation_r.append(np.cov(x[:,col],y)[0][1]/ (np.std(x[:,col]) * np.std(y)))
OLS Regression Results
==============================================================================
Dep. Variable: y R-squared: 0.778
Model: OLS Adj. R-squared: 0.776
Method: Least Squares F-statistic: 344.3
Date: Wed, 29 Sep 2021 Prob (F-statistic): 7.72e-34
Time: 21:56:20 Log-Likelihood: -137.09
No. Observations: 100 AIC: 278.2
Df Residuals: 98 BIC: 283.4
Df Model: 1
Covariance Type: nonrobust
==============================================================================
coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------
const -0.0377 0.097 -0.389 0.698 -0.230 0.155
x1 1.9989 0.108 18.556 0.000 1.785 2.213
==============================================================================
Omnibus: 3.621 Durbin-Watson: 2.174
Prob(Omnibus): 0.164 Jarque-Bera (JB): 3.626
Skew: 0.448 Prob(JB): 0.163
Kurtosis: 2.743 Cond. No. 1.17
==============================================================================
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
[6]:
('approx_t_bhat', 18.725931937448564)
[7]:
import numpy as np
from scipy import stats
import pandas as pd
from pprint import pprint
np.random.seed(1)
n = 100
p = 5
# TO BUILD IN PYTHON
# X = np.random.normal(np.arange(1,p+1), 1, (n,p))
# eps = np.random.normal(0,1,n)
# beta_star = np.array([1.0,0.0,2.0,-0.5,0.5,1.0])[:p+1]
# y = np.dot(xvec, beta_star) + eps
# Read in from R to ensure same data
if p == 5:
filename = "_static//datamining_hw2_question3.csv"
df = pd.read_csv(filename, index_col=0)
X = df[[f'x.{i}' for i in range(1,p+1)]].values
y = df['y'].values
else:
filename = "_static//datamining_hw2_question3c.csv"
df = pd.read_csv(filename, index_col=0)
X = df[['x']].values
y = df['y'].values
xvec = np.hstack((np.vstack(np.ones(len(X))),np.vstack(X)))
m = np.dot(np.linalg.inv(np.dot(xvec.T, xvec)), np.dot(xvec.T, y))
print('coefficients:', m)
yhat = np.dot(xvec, m)
analyze_linear_model(y, yhat, xvec, n, p)
import matplotlib.pyplot as plt
plt.plot(y)
plt.plot(yhat)
r2 = np.corrcoef(y,yhat) ** 2
r2
coefficients: [ 0.80429471 -0.01880692 2.07708222 -0.46570561 0.49094525 0.96793266]
{'F(Bhat)': 465.3294242077351,
'MSE': 0.9608057901465713,
'RSE': 4.80140017057294,
'SSE': 91.2765500639243,
'SSR': 2259.2374726018297,
'SST': 2350.5140226657495,
'Sd(Bhat)': 0.23273137162305024,
'Var(Bhat)': 0.054163891337546316,
'p_ftest(Bhat)': 0.9999999999999999,
'p_ttest(Bhat)': array([8.21720809e-04, 9.35763387e-01, 3.28626015e-14, 4.82409864e-02,
3.75311950e-02, 7.00777143e-05]),
'r': [nan,
0.7231431404804363,
0.9424031322894084,
0.6299604540858132,
0.7127929784445699,
0.8480567254338526],
'r2': 0.9611674088374925,
't(Bhat)': array([ 3.45589297, -0.08080958, 8.92480546, -2.00104357, 2.10949323,
4.1590124 ])}
OLS Regression Results
==============================================================================
Dep. Variable: y R-squared: 0.961
Model: OLS Adj. R-squared: 0.959
Method: Least Squares F-statistic: 465.3
Date: Wed, 29 Sep 2021 Prob (F-statistic): 1.17e-64
Time: 21:56:21 Log-Likelihood: -137.33
No. Observations: 100 AIC: 286.7
Df Residuals: 94 BIC: 302.3
Df Model: 5
Covariance Type: nonrobust
==============================================================================
coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------
const 0.8043 0.234 3.438 0.001 0.340 1.269
x1 -0.0188 0.099 -0.191 0.849 -0.215 0.177
x2 2.0771 0.095 21.926 0.000 1.889 2.265
x3 -0.4657 0.088 -5.263 0.000 -0.641 -0.290
x4 0.4909 0.092 5.310 0.000 0.307 0.675
x5 0.9679 0.084 11.474 0.000 0.800 1.135
==============================================================================
Omnibus: 1.726 Durbin-Watson: 2.009
Prob(Omnibus): 0.422 Jarque-Bera (JB): 1.664
Skew: -0.225 Prob(JB): 0.435
Kurtosis: 2.555 Cond. No. 18.2
==============================================================================
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
<ipython-input-6-9a69040a4fca>:61: RuntimeWarning: invalid value encountered in double_scalars
correlation_r.append(np.cov(x[:,col],y)[0][1]/ (np.std(x[:,col]) * np.std(y)))
[7]:
array([[1. , 0.96116741],
[0.96116741, 1. ]])

TODO: add CI for betas, try out MLE solution (maximize log likelihood across parameter lambda in a boxcox), add H leverage, add standard error r, plot standandard error (y) vs leverage (x) and add cookes distance lines